

April
2025
This past summer Interrupt Labs ran an internship as part of the Defence Industry Internship Program (DIIP).
This article showcases the work of our intern Ashleigh Johannes, who developed a Binary Ninja plugin called HeaderQuery that imports function parameter and type information from C header files. We’ve open-sourced the plugin here.
Introduction
For the past three months I have been a Vulnerability Research (VR) intern at Interrupt Labs in Australia.
As part of my self-directed project, I needed a way to import information from source code into my Binary Ninja database.
For example, to import function parameter/type information natively in Binary Ninja you typically provide a header file along with
the necessary compiler flags and macros.
However, I quickly realized this required deducing relevant compiler directives and include flags. Even when I could do this, I ended up with a large number of types that were only relevant to the internal logic of the external library, cluttering my database.
So I went about developing a plugin, HeaderQuery, for importing function parameter and type information from C header files,
even if I didn't know the necessary compiler flags and macros required to preprocess the code.
Design
Parsing C Code
Importing types and function parameters into Binary Ninja requires parsing information from header files.
The Binary Ninja API has some capacity for this, but it cannot leverage pre-existing types in the Binary View (bv).
I decided to use Tree-sitter to break headers down into a syntax tree to extract this information from the tree.
Tree-sitter is an incremental parsing library and parser generator tool that builds concrete syntax trees from source code.
Importantly, it is possible to build a tree from code even if that code doesn't compile (e.g., it contains syntax errors),
opening up the possibility to import information from incomplete codebases.
After generating a tree with Treesitter, we can query the tree for specific patterns, allowing us to filter for functions and types without
manually walking every node of the tree.
We can write queries as broad or specific as we like, which makes them a flexible tool for finding the information we are interested in.
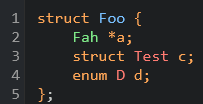
Take the following code example:
Tree-sitter produced the following syntax tree:
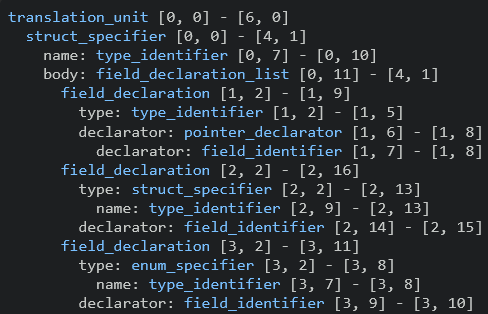
We can then query this tree for information like the name of the struct:
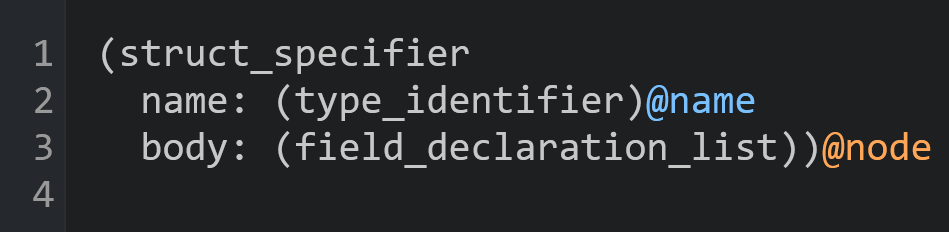
This query will match any struct_specifier and extract the name of the struct.
It will also extract the node, which is referring to the Tree-sitter node representing this struct:
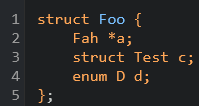
Now we also want to capture fields.
Because fields vary greatly between structs, we don't want to match for these at the top level.
Instead, we write a few more queries to capture different varieties of fields.
We can then query the node captured above, so the impact of running separate queries is minimal.
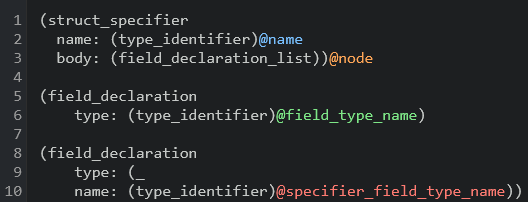
Which we can see highlighted below:
Importing into Binary Ninja
Once we've parsed this information using Treesitter, we search the Binary View (bv) to find all external functions that exist in both the bv and the functions we've found in the header.
These are the functions for which we want to import their parameters.
Then, we search each of those functions for their dependencies, so we can also import those types.
Stubs and Type Creation
It's not quite as simple as supplying the source code to Binary Ninja to import a function or type.
First, we must make sure that all dependencies of a function exist.
For example, we cannot update the parameters of a function foo(A a) if we have not yet imported A.
And we cannot import A until we have imported its dependencies.
To get around this, we first create a stub of each type that we depend upon.
This stub is an empty struct or enum, using the name of the dependency.
Now, we can assign parameters to a function because the type already exists, even if we haven't yet imported the fields of the type.
Together, this allows us to check the existence of types within the bv, and leverage them when we import other types and functions into Binary Ninja.
Logical Flow
Putting each of these steps together:
- Use Tree-sitter to build the concerete syntax tree (CST).
- Extract the function and type information from the CST.
- Find the functions that exist in both the CST and
bv. - Repeat 1-3 for all headers.
- Find all dependencies of functions identified in 3.
- Create the
bvstubs, and then types for each dependency. - Annotate the functions in the Binary View.
- Propagate parameter names from annotated functions up the call tree.
- Report errors and other useful information back to the user.
User Experience
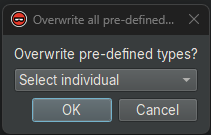
When the user runs HeaderQuery, they can choose whether to overwrite pre-existing types, or select individual types to overwrite:
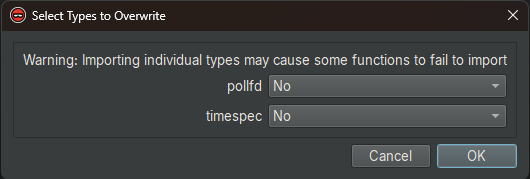
Results are usually best when all types are imported from the header, but a user can optionally retain work they've already done to reverse or
annotate types by choosing not to overwrite those types.
Output
After we've applied the function parameters, imported their dependencies, and propagated parameter names to caller functions,
we report the successes and failures back to the user in a new tab so they have a reference for what was imported and can manually
review any imports that didn't succeed.
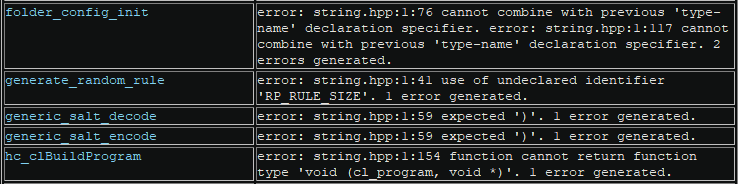
Error messages are shown alongside function or type names, with a brief summary of some of the common errors users may come across. The user can click on a function name to be redirected to the location of that function within the Binary Ninja database.
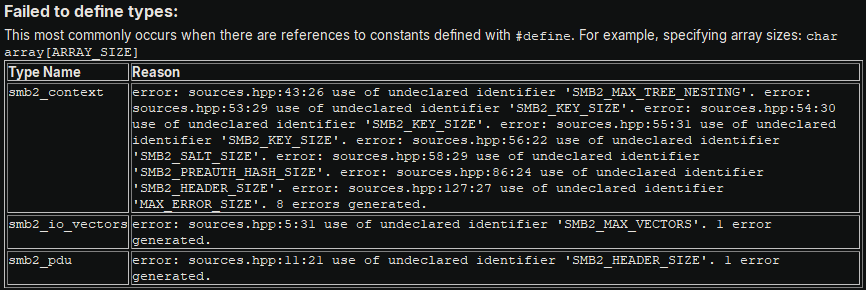
Below is an example of errors from importing functions:
A similar table is displayed for errors from importing types:
Blank stubs are also reported to notify the user that this type isn't necessarily intended to be blank, but that there was not sufficient
information within the header to import fields.
Most often this is due to the lack of any sort of preprocessing.
Caveats
There are a few cases that HeaderQuery cannot support.
First, it only parses C code; it cannot parse C++. This is something that could be implemented in the future,
but would require a separate Tree-sitter grammar. It would also require a new set of queries, as the tree structure differs across grammars. As such, supporting C++ was out of scope for the timeline of the project.
The second pertinent case is that HeaderQuery does not handle macros in C headers.
Macros are captured by Treesitter but are challenging to parse, and trying to process them starts to lead us back towards identifying the
necessary compiler flags to use Binary Ninja's builtin header importer (and, if the header fails the preprocessor, we're totally out of luck).
Finally, the third case is duplicate definitions due to conditionals. HeaderQuery will take the first occurrence of each type it finds, and ignore and future occurrences. If the user needs to process these conditionals, they will get better mileage by using the builtin header importer and defining the necessary
macros and compiler flags.
Final Thoughts
Overall, HeaderQuery achieves my goals.
The results for some libraries are significantly more useful than others depending on the number of macros used, but it succeeds in reducing the
number of libraries that a researcher might have to investigate and import manually.
It only imports the types that are strictly necessary for the functions that appear in the Binary View, so the user defined types in the database are kept as few as possible.
This makes it easier to navigate and develop an understanding of the information flow within a binary.
There is opportunity for further work to be done to handle simple macro cases such as constants, and support C++ headers to make HeaderQuery helpful across more cases.
HeaderQuery has been a useful tool to simplify and improve my workflow, and I hope that other researchers will find it useful too.
You can check it out here!
